tomcat字符编码深度分析
昨天发的解决中文乱码总结一文列举了各方法,却没讲原理。并且还有一处遗漏的配置的地方没写。今天又学习了下,希望能彻底搞明白这个问题,如有不对还请大家指正。
先补充下配置,在tomcat的server.xml的Connector标签里可以配置如下两个属性: URIEncoding与useBodyEncodingForURI,在tomcat/webapp/docs/config/http.html有对这两个属性的详解,
URIEncoding This specifies the character encoding used to decode the URI bytes, after %xx decoding the URL. If not specified, ISO-8859-1 will be used.
useBodyEncodingForURI This specifies if the encoding specified in contentType should be used for URI query parameters, instead of using the URIEncoding.
意思就是说useBodyEncodingForURI=true优先于URIEncoding配置,可用Request.setCharacterEncoding设置每个请求的编码,默认是不配置的。而URIEncoding的默认配置是ISO-8859-1,所以上文的解析方法是new String(paramVal.getBytes(“ISO-8859-1”),”UTF-8”)这样的方法来解析的。
下面讲解下tomcat是的转换过程,本文源码摘自apache-tomcat-6.0.26。
1. 页面我们传的是:name=%E5%BC%A0%E4%B8%89
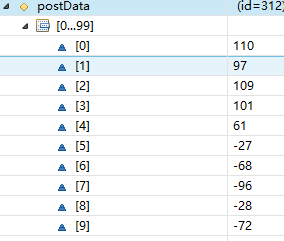
2. tomcat中实现HttpServletRequest的类是org.apache.catalina.connector.Request,数据传到tomcat开始是字节数组,存储在org.apache.catalina.connector.Request的postData属性中,如下图,正好是“name=张三”的字节数组
3. 这个类里需要把先过来的数据存储到Parameter成员中,以便程序使用request.getParameter()时使用,将字节数组转为字符串的方法是parseParameters[line:2498],源码是这样的:
取配置的编码:
4. 将2的字节数组与3的编码形成最终字符串。
源码实现为:Request[line:2572]进入org.apache.tomcat.util.http.Parameters.processParameters(formData, 0, len);实现其功能
最后我又使用了昨天的用例,在同时配置了filter与 server.xml的情况下进行了测试。使用firefox发现在get方式下即使不使用encodeURI函数,浏览器一样会转为utf-8编码请求。测试结果如下:
.jpg?imageView2/2/w/800)
由上图可知,在两种配置都有的情况下,不需要前台和后台写什么编码解码代码即可正常打印结果,反倒是不正确使用了函数会导致乱码。
文/程忠 浏览次数:0次 2015-01-23 13:16:33
先补充下配置,在tomcat的server.xml的Connector标签里可以配置如下两个属性: URIEncoding与useBodyEncodingForURI,在tomcat/webapp/docs/config/http.html有对这两个属性的详解,
URIEncoding This specifies the character encoding used to decode the URI bytes, after %xx decoding the URL. If not specified, ISO-8859-1 will be used.
useBodyEncodingForURI This specifies if the encoding specified in contentType should be used for URI query parameters, instead of using the URIEncoding.
意思就是说useBodyEncodingForURI=true优先于URIEncoding配置,可用Request.setCharacterEncoding设置每个请求的编码,默认是不配置的。而URIEncoding的默认配置是ISO-8859-1,所以上文的解析方法是new String(paramVal.getBytes(“ISO-8859-1”),”UTF-8”)这样的方法来解析的。
下面讲解下tomcat是的转换过程,本文源码摘自apache-tomcat-6.0.26。
1. 页面我们传的是:name=%E5%BC%A0%E4%B8%89
<form action="submit.jsp" method="post" id="sform">
<input type="text" name="name" value="张三"/>
<input type="submit" value="提交" >
</form>2. tomcat中实现HttpServletRequest的类是org.apache.catalina.connector.Request,数据传到tomcat开始是字节数组,存储在org.apache.catalina.connector.Request的postData属性中,如下图,正好是“name=张三”的字节数组
3. 这个类里需要把先过来的数据存储到Parameter成员中,以便程序使用request.getParameter()时使用,将字节数组转为字符串的方法是parseParameters[line:2498],源码是这样的:
取配置的编码:
String enc = getCharacterEncoding();//这个是取在Filter中设置的编码
boolean useBodyEncodingForURI = connector.getUseBodyEncodingForURI();//这个是在server.xml中设置
if (enc != null) {
parameters.setEncoding(enc);
if (useBodyEncodingForURI) {
parameters.setQueryStringEncoding(enc);//这里是对Get方式的编码设置
}
} else {
//如果没有设置filter编码那么就取下面默认的ISO-8859-1
parameters.setEncoding(org.apache.coyote.Constants.DEFAULT_CHARACTER_ENCODING);
if (useBodyEncodingForURI) {
parameters.setQueryStringEncoding(org.apache.coyote.Constants.DEFAULT_CHARACTER_ENCODING);
}
}4. 将2的字节数组与3的编码形成最终字符串。
源码实现为:Request[line:2572]进入org.apache.tomcat.util.http.Parameters.processParameters(formData, 0, len);实现其功能
最后我又使用了昨天的用例,在同时配置了filter与 server.xml的情况下进行了测试。使用firefox发现在get方式下即使不使用encodeURI函数,浏览器一样会转为utf-8编码请求。测试结果如下:
由上图可知,在两种配置都有的情况下,不需要前台和后台写什么编码解码代码即可正常打印结果,反倒是不正确使用了函数会导致乱码。
相关阅读
微信扫描-捐赠支持

加入QQ群-技术交流

评论:
↓ 广告开始-头部带绿为生活 ↓
↑ 广告结束-尾部支持多点击 ↑