智能小车29:自动驾驶与机器学习
要让我的小车能自动去倒一杯咖啡。需要的做的事还有很多,其中一个很难的问题就是自动驾驶,怎么才能让我的小车自动驾驶到咖啡机旁边去呢?
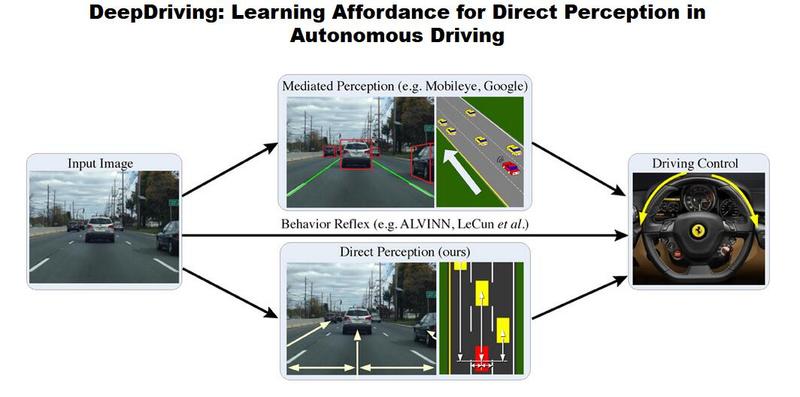
这是一个不借助mobileye之类硬件的一个软件技术。直接通过图像识别来判断和控制汽车。
2.comma.ai ,一个便宜的硬件+开源软件
网址:https://comma.ai/
3. 市面上已经有的产品,如"那狗N2 ADAS"

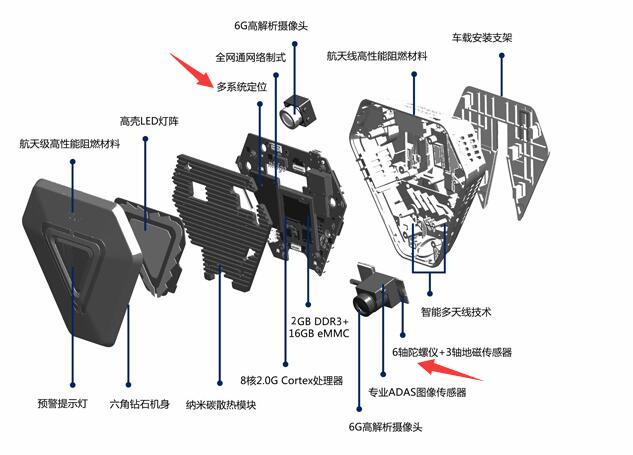
可以看得出,也是个硬件,不过是以摄像头为主,其它硬件为辅的。再加上自己的软件分析处理。
我想了想其实硬件并不复杂,主要是软件如何识别这些图片和这些传感器信号?查了些资料,图片识别技术如果不是人工标注特征,那么就要靠深度学习。而深度学习又以机器学习技术为基础。所以要搞明白这些,机器学习必须搞明白。
先了解了机器学习的一些基本术语
数据集:一组记录的集合,如有一组西瓜的数据(色泽=青绿,根蒂=蜷缩,敲声=浊响)
示例/样本:一条记录,如上面的色泽 =青绿
属性/特征:如上面的色泽
属性值:如上面的青绿
属性空间/样本空间/输入空间:属性张成的空间,如上面的(色泽、根蒂、敲声作为三个坐标轴,则它们张成一个用于描述西瓜的三维空间)
每个西瓜都可在这个空间中找到自己的位置,由于空中的每个点对应一个坐标向量,因此这一个示例也做“特征向量"
维度:上面的例子就是3
学习/训练:从数据中学得模型的过程,
训练数据:训练过程中使用的数据
训练样本:训练中的每组数据
训练集:训练中样本的集合
假设:觉得模型对应了关于数据的某种潜在的规律
真相/真实:这个规律本身
学习器:模型
标记:关于示例结果的信息,例如下面的样本中的结果是好瓜((色泽=青绿,根蒂=蜷缩,敲声=浊响),好瓜).
样例:拥有了标记信息的示例。
标记空间/输出空间:所有标记的集合.
如果用(Xi,Yi)表示第i个样例,其中Yi(归属于γ)是示例Xi的标记, γ就是标记空间.
分类:预测的是离散值的任务,例如好瓜、坏瓜
回归:预测的是连续值的任务,例如西瓜成熟度是0.9,0.5,0.3
二分类:只有两个分类的任务,其中一个正类,另一个是反类
测试:学得模型后,使用其进行预测的过程
例如在觉得f后,对测试例x,可得到其预测标记y=f(x).
聚类:即将训练集中的西瓜分成若干组,每组称为一个"簇";这些自动形成的簇可能对应一些潜在的概念划分,例如"浅色瓜",”本地瓜",这就是2个聚类。
监督学习与无监督学习,分类与聚类分别属于前面两种。也就是说聚类比较高级,我们不知道能训练出什么结果(标记)来,而分类是事先定好的。
泛化:分类/簇划分能适用于没在训练集中出现的样本,觉得模型适用于新样本的能力。
好了基本术语学习完毕,上面的术语出处是周志华的《机器学习》