java生成Word文件的三种方式
前期调研的itext,生成效果不行,版本太老,就不发出来了。
1.使用poi库生成
引入pom.xml
<dependency> <groupid>org.apache.poi</groupid> <artifactid>poi</artifactid> <version>4.1.0</version> </dependency> <dependency> <groupid>org.apache.poi</groupid> <artifactid>poi-ooxml</artifactid> <version>4.1.0</version> </dependency>生成文件代码
XWPFDocument document= new XWPFDocument();
//Write the Document in file system
FileOutputStream out = new FileOutputStream(new File("/Users/xxx/work/xxx/create_toc.docx"));
//添加标题
XWPFParagraph titleParagraph = document.createParagraph();
//设置段落居中
titleParagraph.setAlignment(ParagraphAlignment.CENTER);
XWPFRun titleParagraphRun = titleParagraph.createRun();
titleParagraphRun.setText("Java PoI");
titleParagraphRun.setColor("000000");
titleParagraphRun.setFontSize(20);
//段落
XWPFParagraph firstParagraph = document.createParagraph();
firstParagraph.getStyleID();
firstParagraph.setStyle("Heading1");
XWPFRun run = firstParagraph.createRun();
run.setText("段落1。");
run.setColor("696969");
run.setFontSize(18);
//段落
XWPFParagraph firstParagraph1 = document.createParagraph();
firstParagraph.setStyle("Heading1");
XWPFRun run1 = firstParagraph1.createRun();
run1.setText("段落2");
run1.setColor("696969");
run1.setFontSize(16);
document.createTOC();
document.write(out);
out.close();这里有setStyle的参数Heading1,不知道哪里来的吧。看这里:word格式参考:http://www.ecma-international.org/publications/standards/Ecma-376.htm即使有这个,我也没搞定样式问题,主要是有html的富文本内容,用这库完全不知道怎么做。
修改里面的段落,复制段落
package com.xx.utils;
import cn.afterturn.easypoi.entity.ImageEntity;
import cn.afterturn.easypoi.util.PoiPublicUtil;
import cn.afterturn.easypoi.word.parse.excel.ExcelMapParse;
import org.apache.commons.lang3.StringUtils;
import org.apache.poi.xwpf.usermodel.*;
import org.apache.xmlbeans.XmlCursor;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public abstract class PoiUtil {
public abstract void insertNewParagraph(XWPFDocument document, int insertPos, XmlCursor insertCursor, XWPFParagraph paragraphTemplate) throws Exception;
public void insertNewParagraphDefault(XWPFDocument document, int insertPos, XmlCursor insertCursor, XWPFParagraph paragraphTemplate) throws Exception{
//倒序加,为了适应insertNewParagraph游标值
for(int k=9;k>7;k--) {
//插入是前插,也就是说插入后,插入时的XmlCursor会变成新值
XWPFParagraph newParagraph = document.insertNewParagraph(insertCursor);
copyParagraph(paragraphTemplate, newParagraph);
//List<XWPFRun> run=addNewParagraph.getRuns();
String key="addSeq";
final String val=String.valueOf(k);
Map<String,Object> map=new HashMap<String,Object>(){{
put(key,val);
}};
setVal(newParagraph,map);
//更新插入下标
insertCursor=newParagraph.getCTP().newCursor();
insertPos++;
}
//移除模板段落
document.removeBodyElement(insertPos);
}
public void replaceParagraph(XWPFDocument document,String paragraphStartFlag) throws Exception{
List<IBodyElement> pgraph=document.getBodyElements();
int insertPos=-1;
XmlCursor insertCursor=null;
XWPFParagraph paragraphTemplate=null;
for(int i=0;i<pgraph.size();i++){
IBodyElement element=pgraph.get(i);
BodyElementType type = element.getElementType();
if (type == BodyElementType.PARAGRAPH && element instanceof XWPFParagraph) {
//g.getBody().getParagraphs().get(7).getParagraphText()
XWPFParagraph g=(XWPFParagraph)element;
System.out.println(i + " " + g.getParagraphText());
if (g.getParagraphText().trim().startsWith(paragraphStartFlag)) {
insertCursor = g.getCTP().newCursor();
paragraphTemplate = g;
insertPos = i;
}
}
}
if(insertCursor!=null) {
insertNewParagraph(document,insertPos,insertCursor,paragraphTemplate);
}
}
private void copyParagraph(XWPFParagraph source,XWPFParagraph target) {
// 设置段落样式
target.getCTP().setPPr(source.getCTP().getPPr());
// 添加Run标签
for (int pos = 0; pos < target.getRuns().size(); pos++) {
target.removeRun(pos);
}
for (XWPFRun s : source.getRuns()) {
XWPFRun targetrun = target.createRun();
copyRun(targetrun, s);
}
}
private void copyRun(XWPFRun target, XWPFRun source) {
target.getCTR().setRPr(source.getCTR().getRPr());
// 设置文本
target.setText(source.text());
}
public void setVal(XWPFParagraph paragraph,Map<String,Object> map) throws Exception{
Boolean isfinde = false;
XWPFRun currentRun = null;
String currentText = "";
List<Integer> runIndex = new ArrayList();
for(int i = 0; i < paragraph.getRuns().size(); ++i) {
XWPFRun run = (XWPFRun) paragraph.getRuns().get(i);
String text = run.getText(0);
if (!StringUtils.isEmpty(text)) {
if (isfinde) {
currentText = currentText + text;
if (currentText.indexOf("{{") == -1) {
isfinde = false;
runIndex.clear();
} else {
runIndex.add(i);
}
if (currentText.indexOf("}}") != -1) {
changeValues(paragraph, currentRun, currentText, runIndex, map);
currentText = "";
isfinde = false;
}
} else if (text.indexOf("{{") >= 0) {
currentText = text;
isfinde = true;
currentRun = run;
} else {
currentText = "";
}
if (currentText.indexOf("}}") != -1) {
changeValues(paragraph, currentRun, currentText, runIndex, map);
isfinde = false;
}
}
}
}
private void changeValues(XWPFParagraph paragraph, XWPFRun currentRun, String currentText, List<Integer> runIndex, Map<String, Object> map) throws Exception {
if (currentText.contains("fe:") && currentText.startsWith("{{")) {
currentText = currentText.replace("fe:", "").replace("{{", "").replace("}}", "");
String[] keys = currentText.replaceAll("\\s{1,}", " ").trim().split(" ");
List list = (List) PoiPublicUtil.getParamsValue(keys[0], map);
list.forEach((objx) -> {
if (objx instanceof ImageEntity) {
currentRun.setText("", 0);
ExcelMapParse.addAnImage((ImageEntity)objx, currentRun);
} else {
PoiPublicUtil.setWordText(currentRun, objx.toString());
}
});
} else {
Object obj = PoiPublicUtil.getRealValue(currentText, map);
if (obj instanceof ImageEntity) {
currentRun.setText("", 0);
ExcelMapParse.addAnImage((ImageEntity)obj, currentRun);
} else {
currentText = obj.toString();
PoiPublicUtil.setWordText(currentRun, currentText);
}
}
for(int k = 0; k < runIndex.size(); ++k) {
((XWPFRun)paragraph.getRuns().get((Integer)runIndex.get(k))).setText("", 0);
}
runIndex.clear();
}
}
依赖pom.xml<dependency>
<groupId>cn.afterturn</groupId>
<artifactId>easypoi-base</artifactId>
<version>4.3.0</version>
<exclusions>
<exclusion>
<artifactId>guava</artifactId>
<groupId>com.google.guava</groupId>
</exclusion>
<exclusion>
<artifactId>poi-ooxml</artifactId>
<groupId>org.apache.poi</groupId>
</exclusion>
<exclusion>
<artifactId>poi-ooxml-schemas</artifactId>
<groupId>org.apache.poi</groupId>
</exclusion>
<exclusion>
<artifactId>poi</artifactId>
<groupId>org.apache.poi</groupId>
</exclusion>
</exclusions>
</dependency>使用package com.xx;
import cn.afterturn.easypoi.word.entity.MyXWPFDocument;
import com.xx.PoiUtil;
import org.apache.poi.xwpf.usermodel.*;
import org.apache.xmlbeans.XmlCursor;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
public class PoiTest {
public static void main(String args[]) throws Exception{
FileInputStream inputStream=new FileInputStream(new File("/Users/chengzhong/code/workspace/cs-monitor-platform/indicator/src/main/resources/words/loop.docx"));
String outFile="/Users/chengzhong/code/workspace/cs-monitor-platform/indicator/src/main/resources/words/loop2.docx";
XWPFDocument document= new MyXWPFDocument(inputStream);
PoiTest poiTest=new PoiTest();
FileOutputStream out = new FileOutputStream(new File(outFile));
String paragraphStartFlag="({{addSeq}}){{addName}}";
new PoiUtil(){
@Override
public void insertNewParagraph(XWPFDocument document, int insertPos, XmlCursor insertCursor, XWPFParagraph paragraphTemplate) throws Exception {
this.insertNewParagraphDefault(document, insertPos, insertCursor, paragraphTemplate);
}
}.replaceParagraph(document,paragraphStartFlag);
document.write(out);
out.close();
}
}
模板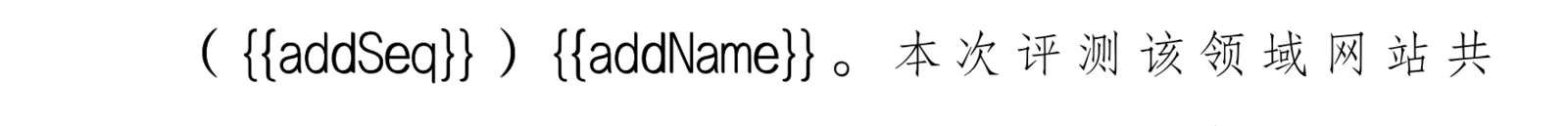
2.直接往返回流里写html,不过response的context-type设置为doc.
业务代码:
StringBuffer sb=new StringBuffer();
sb.append("");
...
sb.append("");
OutputStream out=response.getOutputStream();
out.write(sb.toString().getBytes());
out.flush();设置返回头:String suffix=".doc";
String fileName="文件名";
String recommendedName;
//判断是否是IE11
Boolean flag = request.getHeader("User-Agent").indexOf("like Gecko") > 0;
if (request.getHeader("User-Agent").toLowerCase().indexOf("msie") > 0 || flag) {
recommendedName = URLEncoder.encode(fileName, "UTF-8");//IE浏览器
} else {
//先去掉文件名称中的空格,然后转换编码格式为utf-8,保证不出现乱码,
//这个文件名称用于浏览器的下载框中自动显示的文件名
recommendedName = new String(fileName.replaceAll(" ", "").getBytes("UTF-8"), "ISO8859-1");
}
response.setContentType("application/msword");
response.setHeader("Content-disposition", "attachment;filename=" + recommendedName + (suffix == null ? ".doc" : suffix));
OutputStream ouputStream = response.getOutputStream();
writeDoc(ouputStream,paperVo);
ouputStream.flush();
ouputStream.close();这种方式在windows下的office word,wps都可以支持,但mac的pages不识别这个文件。
3.使用第三方模板库poi-tl
pom.xml引入:
<dependency> <groupId>com.deepoove</groupId> <artifactId>poi-tl</artifactId> <version>1.5.0</version> </dependency>首先建一个.docx的模板文件,例:

这里的{{变量名}}直接可替换为代码里的字符串,“变量名"前面有"+"号表示此处由另一个模板文件生成,并且是数组形式的。
生成代码:
public void create(TextModel tm,String filePath) throws IOException {
tm.setChapters(new DocxRenderData(
new File("folder/doc/template/chapters_segment.docx"), tm.getChapterList()));
for(AttachSegment cs:tm.getChapterList()) {
cs.setQuestions(new DocxRenderData(
new File("folder/doc/template/question_segment.docx"), cs.getQuestionList()));
}
XWPFTemplate template = XWPFTemplate
.compile("folder/doc/template/text_template.docx").render(tm);
File file=new File(filePath);
if(file.exists()) {
//已存在文件,对其文件名进行"加1"方式重命名
File children[]=file.getParentFile().listFiles();
int nextSeq=1;
int max=-1;
for(File child:children) {
if(child.getName().contains("_")) {
String cName=child.getName();
String numStr=cName.substring(cName.lastIndexOf("_")+1,cName.lastIndexOf(".")).trim();
try {
Integer n=Integer.valueOf(numStr);
if(n>max) {
max=n;
}
}catch(Exception e) {
log.error("导出文件名错误,解析数据异常:"+filePath+ e.getMessage());
}
}
}
if(max!=-1) {
nextSeq=max+1;
}
int end=filePath.lastIndexOf(".");
file=new File(filePath.substring(0,end)+"_"+nextSeq+".docx");
}
FileOutputStream out = new FileOutputStream(file);
template.write(out);
template.close();
out.flush();
out.close();
}这里有个换行问题需要注意,它比较显示显示效果。
1.以\n换行: office,wps正常显示,pages不换行
2.以\r\n换行: office,pages(mac)正常显示,wps 会多显示一个空行
相关阅读
微信扫描-捐赠支持

加入QQ群-技术交流

评论:
↓ 广告开始-头部带绿为生活 ↓
↑ 广告结束-尾部支持多点击 ↑