hadoop的hdfs远程管理
在之前的一篇文章,介绍了怎么搭建hadoop环境,但hdfs配的是本地(localhost)。这与实际应用有些不同,而且开发Java代码也没法在服务器上搞。那么今天就尝试远程用Java访问一下之前的hdfs。
我在aws上搭的hadoop,这些云服务器有个特点,不能把外网ip配到hosts,否则后面的域名没法在hadoop里使用。这样的话,就使用私网ip配域名就好了。
所以服务器上配host:
私网ip(172.x.x.x) hadoop-master
客户端,也是就我们的开发机上host只能配公网ip:
公网ip(3.x.x.x) hadoop-master
备注一下,如果配成了公网ip,并在core-site.xml使用的话,就会报这样的错:
并且start-all.sh执行完后NameNode进程消息
java.net.BindException: Problem binding to [hadoop-master:9000] java.net.BindException: Cannot assign requested address; For more details see: http://wiki.apache.org/hadoop/BindException at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62) at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) at java.lang.reflect.Constructor.newInstance(Constructor.java:423) at org.apache.hadoop.net.NetUtils.wrapWithMessage(NetUtils.java:837) at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:738) at org.apache.hadoop.ipc.Server.bind(Server.java:640) at org.apache.hadoop.ipc.Server$Listener.<init>(Server.java:1210) at org.apache.hadoop.ipc.Server.<init>(Server.java:3103) at org.apache.hadoop.ipc.RPC$Server.<init>(RPC.java:1039) at org.apache.hadoop.ipc.ProtobufRpcEngine2$Server.<init>(ProtobufRpcEngine2.java:430) at org.apache.hadoop.ipc.ProtobufRpcEngine2.getServer(ProtobufRpcEngine2.java:350) at org.apache.hadoop.ipc.RPC$Builder.build(RPC.java:848) at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.<init>(NameNodeRpcServer.java:475) at org.apache.hadoop.hdfs.server.namenode.NameNode.createRpcServer(NameNode.java:857) at org.apache.hadoop.hdfs.server.namenode.NameNode.initialize(NameNode.java:763) at org.apache.hadoop.hdfs.server.namenode.NameNode.<init>(NameNode.java:1014) at org.apache.hadoop.hdfs.server.namenode.NameNode.<init>(NameNode.java:987) at org.apache.hadoop.hdfs.server.namenode.NameNode.createNameNode(NameNode.java:1756) at org.apache.hadoop.hdfs.server.namenode.NameNode.main(NameNode.java:1821) Caused by: java.net.BindException: Cannot assign requested address at sun.nio.ch.Net.bind0(Native Method) at sun.nio.ch.Net.bind(Net.java:444) at sun.nio.ch.Net.bind(Net.java:436) at sun.nio.ch.ServerSocketChannelImpl.bind(ServerSocketChannelImpl.java:225) at sun.nio.ch.ServerSocketAdaptor.bind(ServerSocketAdaptor.java:74) at org.apache.hadoop.ipc.Server.bind(Server.java:623) ... 13 more
好了那么etc/hadoop下的core-site.xml可以配成这样了:
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop-master:9000/</value> </property> </configuration>
启动,jps可以看到NameNode,DataNode进程。
把hdfs-site.xml改成这样:
<configuration>
<property>
<name>dfs.replication</name>
<value>4</value>
<description>设置副本数</description>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///home/ec2-user/soft/hadoop-3.3.0/tmp/hdfs/name</value>
<description>设置存放NameNode的文件路径</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///home/ec2-user/soft/hadoop-3.3.0/tmp/hdfs/data</value>
<description>设置存放DataNode的文件路径</description>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
<description>权限还是不要的好</description>
</property>
<property>
<name>dfs.client.use.datanode.hostname</name>
<value>true</value>
</property>
</configuration>
注意dfs.replication的数量需大于2,=1时报的错忘了。客户端代码,pom.xml:
<dependencies> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>3.8.1</version> <scope>test</scope> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>3.3.0</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>3.3.0</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>3.3.0</version> </dependency> </dependencies>
java代码,这样写:
package net.highersoft.hadoop;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocatedFileStatus;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.RemoteIterator;
public class TestHadoop {
private FileSystem fs;
public static void main(String[] args) {
TestHadoop th = new TestHadoop();
//ec2-user是服务器上的用户名
th.init("ec2-user");
th.mkdir("/usr/chzh/test2");
}
private void init(String user) {
Configuration cfg = new Configuration();
URI uri = null;
try {
uri = new URI("hdfs://hadoop-master:9000");
} catch (URISyntaxException e) {
e.printStackTrace();
}
try {
// 根据配置文件,实例化成DistributedFileSystem
fs = FileSystem.get(uri, cfg, user); // 得到fs句柄
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
/**
* 创建文件夹
*/
public void mkdir(String dir) {
try {
fs.mkdirs(new Path(dir));
} catch (IOException e) {
// 创建目录
e.printStackTrace();
}
}
}执行完后,进入 http://服务器ip:9870/explorer.html#/usr/chzh
就可以看到如下界面了:
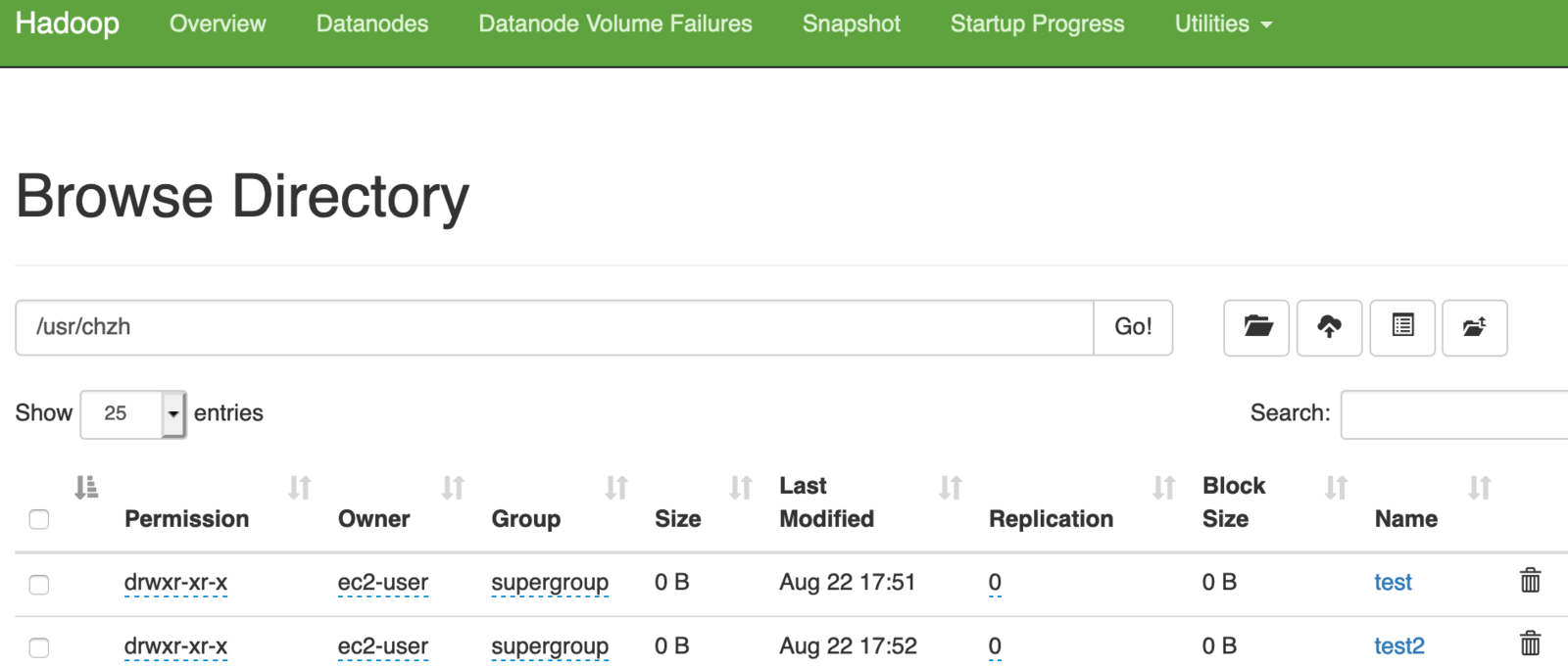
下面就尝试上传文件,本地命令是ok的:
hadoop dfs -put <本地文件>
再用下面的java代码上传就有问题了(init代码与上面的创建文件夹一样):
public class TestHadoop {
private FileSystem fs;
public static void main(String[] args) {
TestHadoop th = new TestHadoop();
//ec2-user是服务器上的用户名
th.init("ec2-user");
//th.mkdir("/usr/chzh/test2");
th.upload("/Users/chengzhong/Downloads/xx.TXT", "/usr/chzh/a.txt");
}
/**
* 上传文件
*/
public void upload(String src, String dst) {
try {
// 上传
fs.copyFromLocalFile(new Path(src), new Path(dst));
} catch (IOException e) {
e.printStackTrace();
}
}
}报错:org.apache.hadoop.ipc.RemoteException(java.io.IOException): File /usr/chzh/a.txt could only be written to 0 of the 1 minReplication nodes. There are 2 datanode(s) running and 2 node(s) are excluded in this operation. at org.apache.hadoop.hdfs.server.blockmanagement.BlockManager.chooseTarget4NewBlock(BlockManager.java:2312) at org.apache.hadoop.hdfs.server.namenode.FSDirWriteFileOp.chooseTargetForNewBlock(FSDirWriteFileOp.java:294) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getAdditionalBlock(FSNamesystem.java:2939) at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.addBlock(NameNodeRpcServer.java:908) at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.addBlock(ClientNamenodeProtocolServerSideTranslatorPB.java:593) at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java) at org.apache.hadoop.ipc.ProtobufRpcEngine2$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine2.java:532) at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:1070) at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:1020) at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:948) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1845) at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2952) at org.apache.hadoop.ipc.Client.getRpcResponse(Client.java:1562) at org.apache.hadoop.ipc.Client.call(Client.java:1508) at org.apache.hadoop.ipc.Client.call(Client.java:1405) at org.apache.hadoop.ipc.ProtobufRpcEngine2$Invoker.invoke(ProtobufRpcEngine2.java:234) at org.apache.hadoop.ipc.ProtobufRpcEngine2$Invoker.invoke(ProtobufRpcEngine2.java:119) at com.sun.proxy.$Proxy9.addBlock(Unknown Source) at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.addBlock(ClientNamenodeProtocolTranslatorPB.java:530) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:422) at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invokeMethod(RetryInvocationHandler.java:165) at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invoke(RetryInvocationHandler.java:157) at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invokeOnce(RetryInvocationHandler.java:95) at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:359) at com.sun.proxy.$Proxy10.addBlock(Unknown Source) at org.apache.hadoop.hdfs.DFSOutputStream.addBlock(DFSOutputStream.java:1090) at org.apache.hadoop.hdfs.DataStreamer.locateFollowingBlock(DataStreamer.java:1867) at org.apache.hadoop.hdfs.DataStreamer.nextBlockOutputStream(DataStreamer.java:1669) at org.apache.hadoop.hdfs.DataStreamer.run(DataStreamer.java:715)
只有一个节点是错误信息数量是这样的:
There are 1 datanode(s) running and 1 node(s) are excluded in this operation
多次浪费时间的失败尝试后,解决了这个问题。其实就是需要多个datanode节点。
那么再申请一台服务器,注意最好是同一局域网的,否则后面就有像我这样的新手搞不定报的错。
开服务器的端口,我看日志需要的端口有好几个。我就开了两台服务器的9000-10000的端口。
在相同路径下安装hadoop3.3.0,进入解压的路径,把环境配置好(/etc/profile,/etc/hosts,${hadoop_home}/etc/hadoop/hadoop-env.sh)只需把master上的core-site.xml,hdfs-site.xml复制过去。
在新服务器上启动数据结点:
./hadoop-daemon.sh start datanode
再把master上的hosts文件改下:
3.xx(公网) hadoop-master 3.xx(公网) hadoop-slave1上面master要用私网ip,这里又得配成公网。这个是试验的结果。改master的hosts后要重启slave的datanode节点。完事后在master的9870网页的datanodes标签下就可以看到两个datanode节点了。
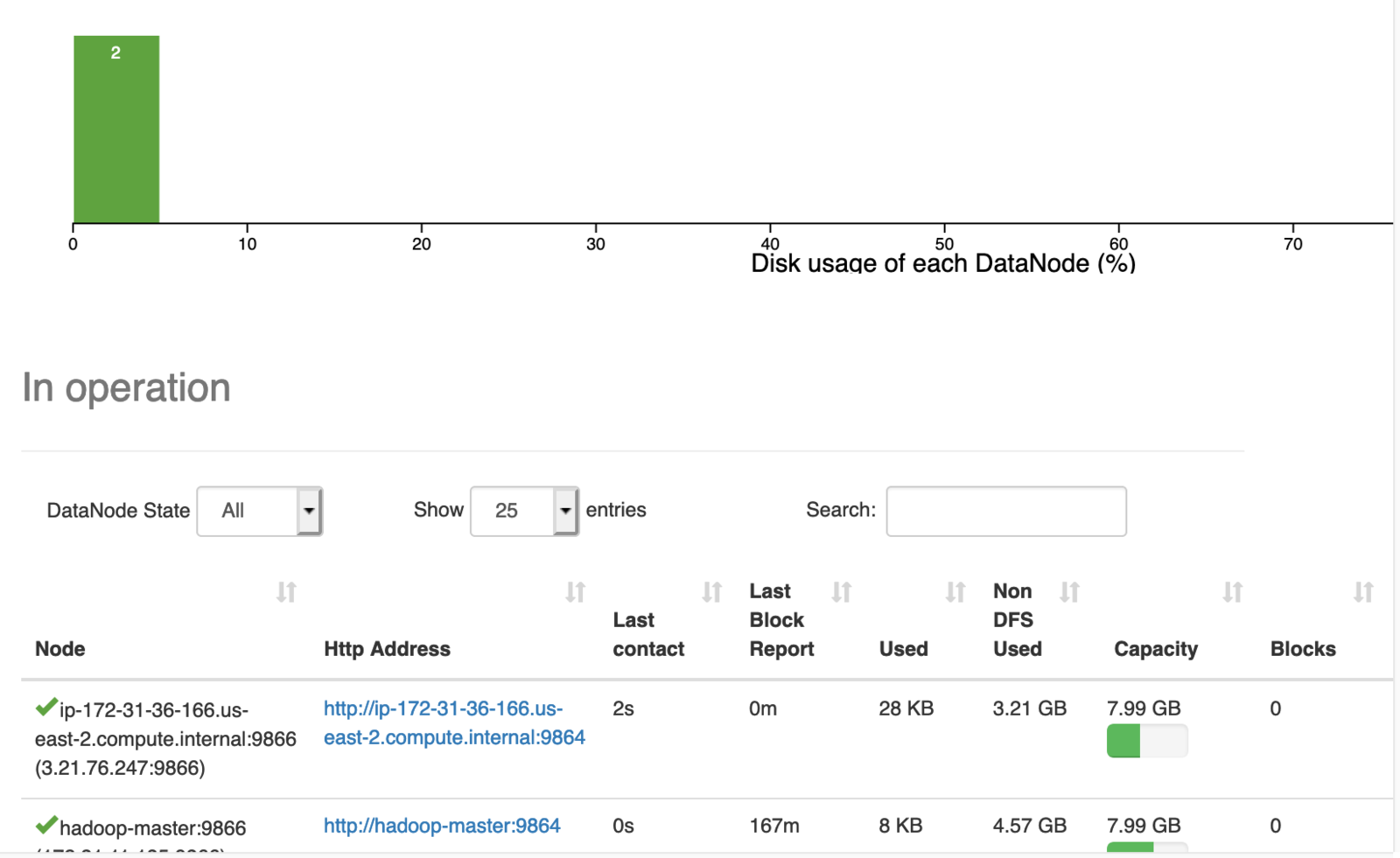
再用上面的代码上传就能成功了:
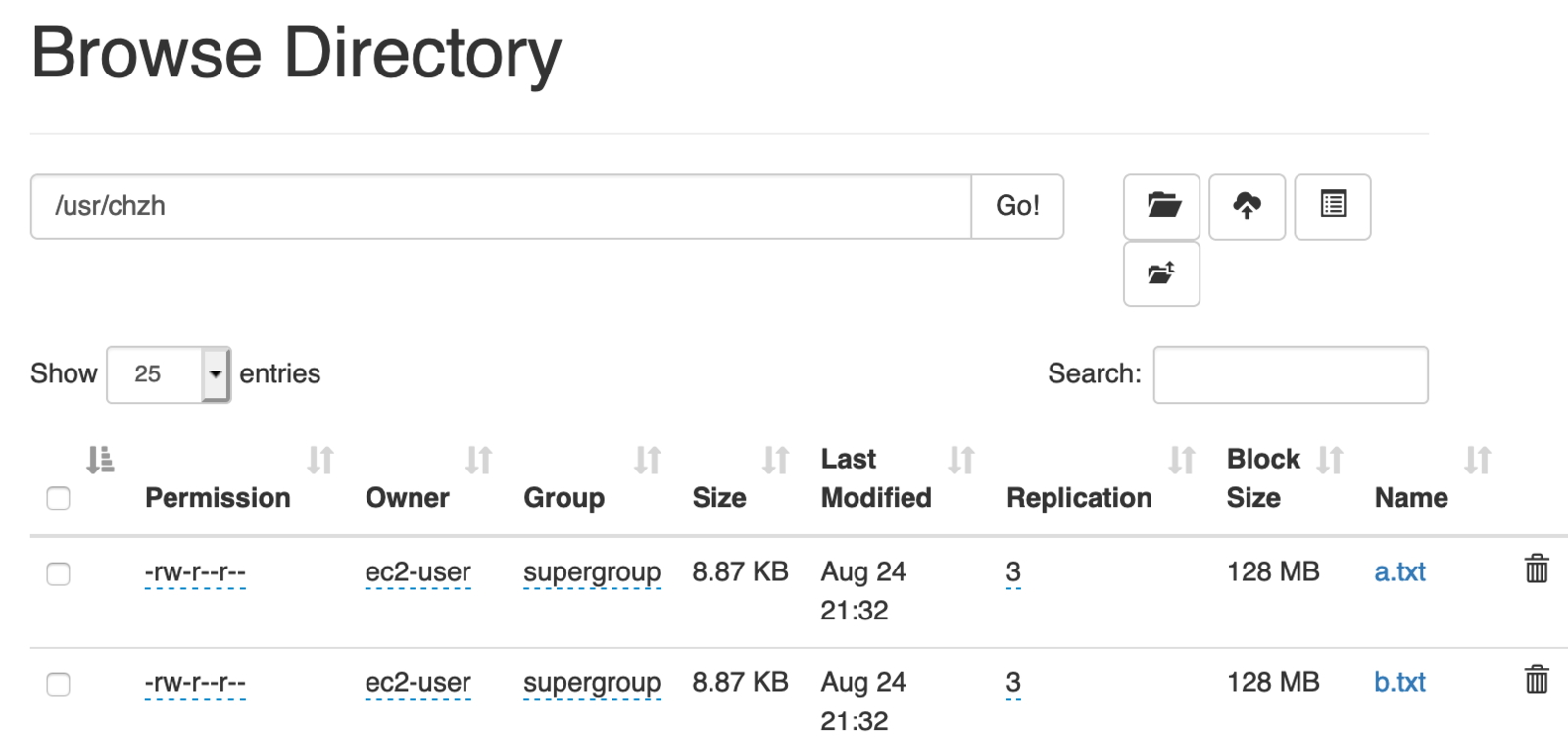
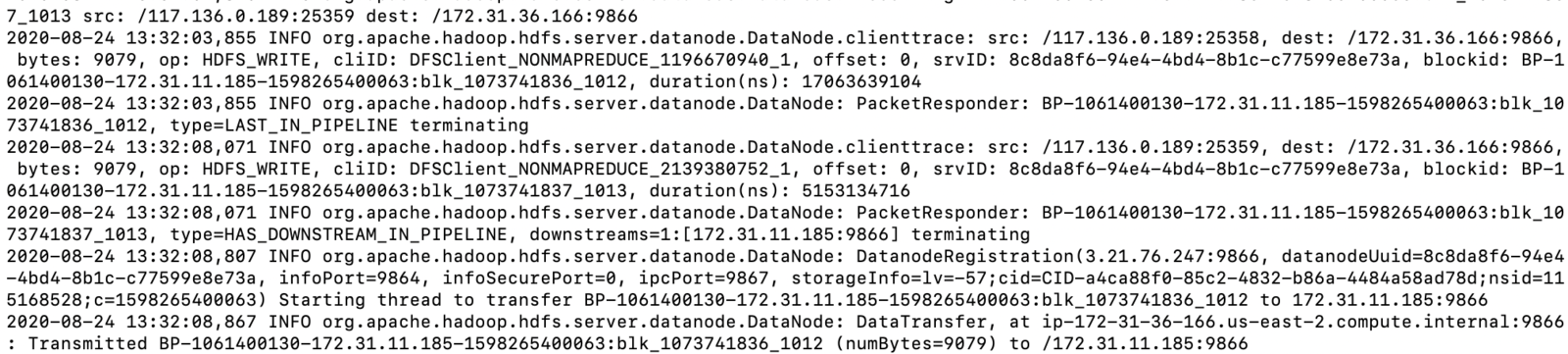
为什么最好同一局域网?从datanode日志可看出些问题,hadoop slave通讯用的域局网ip。
然后可以用spark访问hadoop的hdfs,方法是这样:
进入spark安装目录执行:
./spark-shell
然后输入:
var rdd=sc.textFile("hdfs://192.168.0.103:9000/usr/b.txt")
再用rdd.first()命令查看内容。
注意hadoop3的web服务端口是9870,而hdfs服务端口是9000
注意hadoop如果是在本地,且这样配置的节点:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop-master:9000/</value>
</property>
</configuration>那么hosts里不可这样配:127.0.0.1 hadoop-master
而要配局域网ip
192.168.xx.xx hadoop-master
这样的,因为后面会用代码通过ip来访问端口,如果127.0.0.1则会网络不通。而且192.168.xx.xx的配置也可通过代理访问。