用weka生成树模型与预测
一、用weka gui生成树模型
准备arff文件:
@relation decisiontree_weka
@attribute age {'less30','30to40','more40'}
@attribute income {'high','medium','low'}
@attribute student {'yes','no'}
@attribute credit_rating {'fair','excellent'}
@attribute 'buys_computer' {'yes','no'}
@data
less30,high,no,fair,no
less30,high,no,excellent,no
30to40,high,no,fair,yes
more40,medium,no,fair,yes
more40,low,yes,fair,yes
more40,low,yes,excellent,no
30to40,low,yes,excellent,yes
less30,medium,no,fair,no
less30,low,yes,fair,yes
more40,medium,yes,fair,yes
less30,medium,yes,excellent,yes
30to40,medium,no,excellent,yes
30to40,high,yes,fair,yes
more40,medium,no,excellent,no使用gui的Open file打开这个文件:
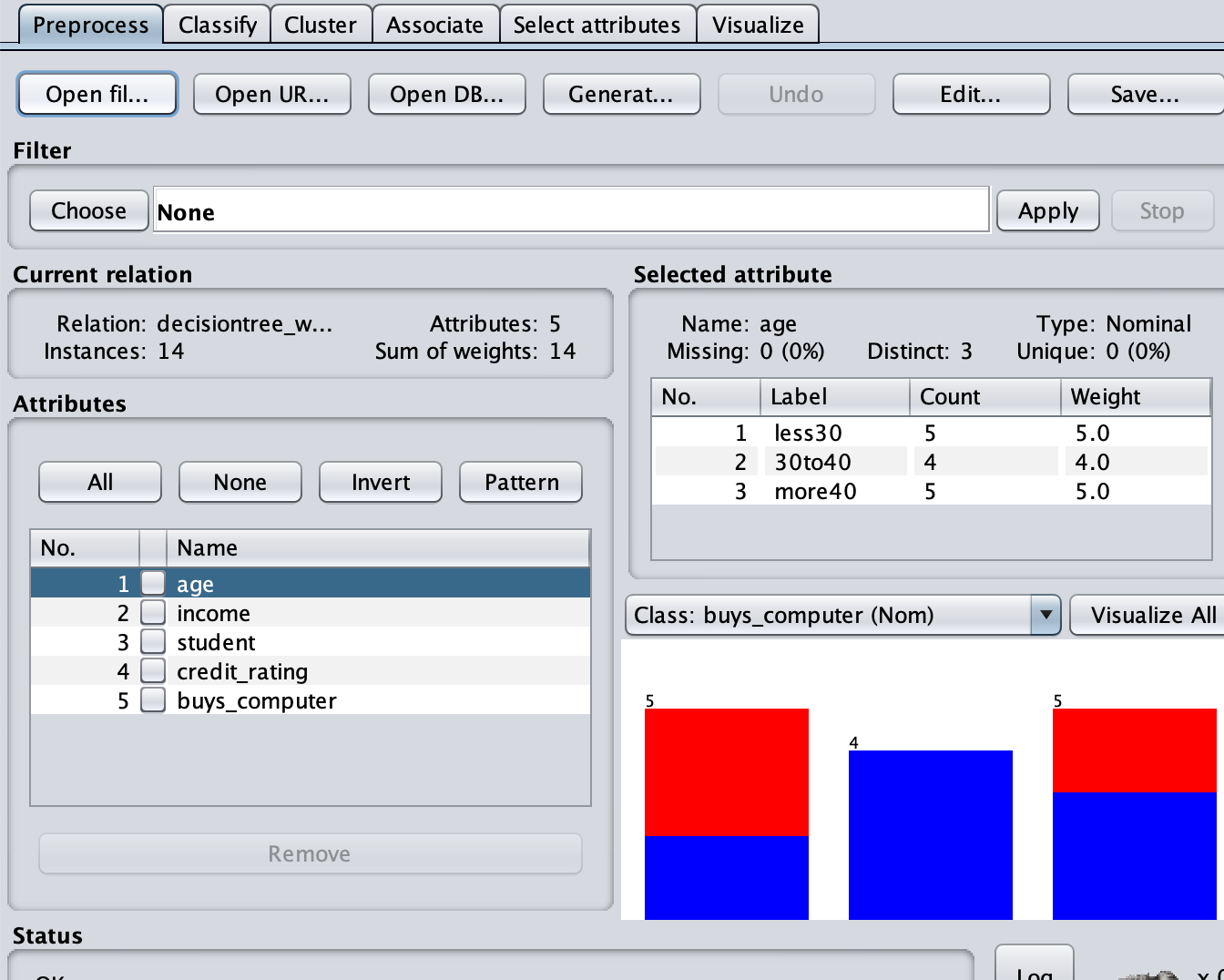
选择树模型:
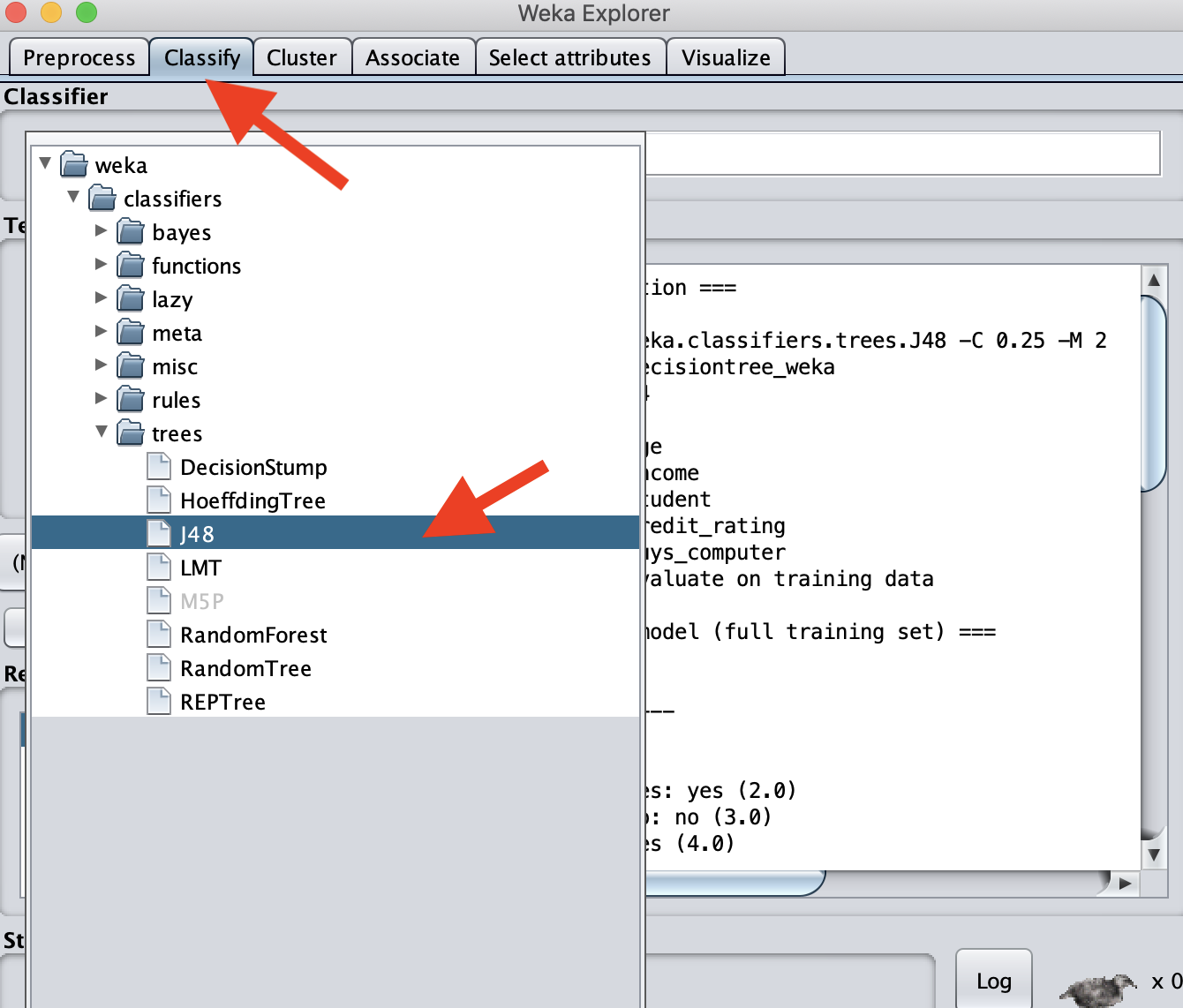
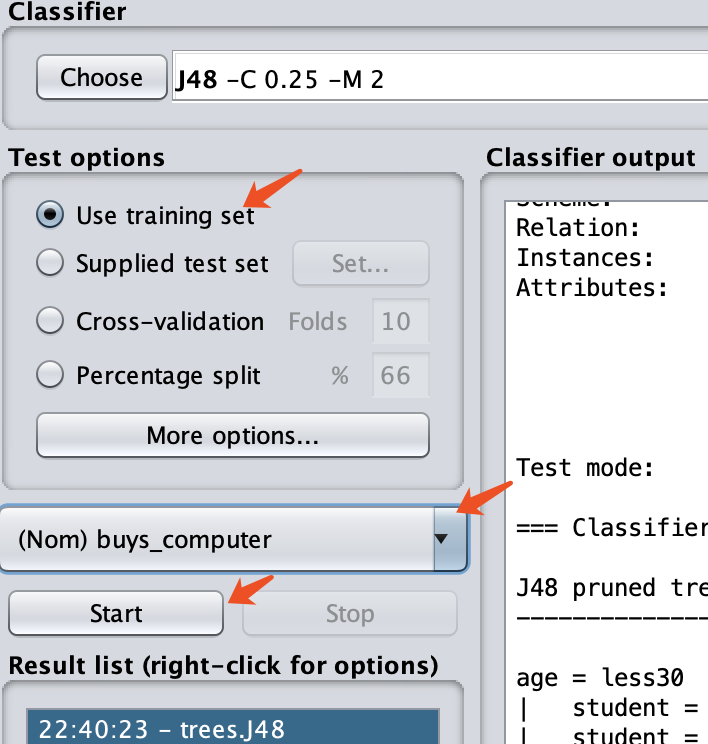
选择,数据全部用于训练,buys_computer为因变量,点击开始:
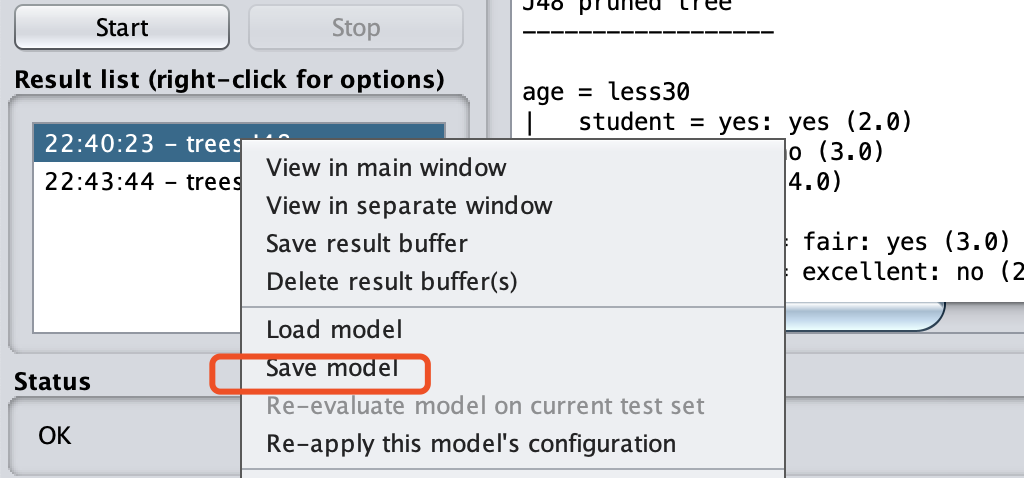
在Result list窗口,在一行上右键选择Save Model,即可导出模型。我导出的文件名为weka_buy_compute_J48.model,后面有用。
在右侧窗口(Classifier output)可以看到生成的树的过程:
=== Run information ===
Scheme: weka.classifiers.trees.J48 -C 0.25 -M 2
Relation: decisiontree_weka
Instances: 14
Attributes: 5
age
income
student
credit_rating
buys_computer
Test mode: evaluate on training data
=== Classifier model (full training set) ===
J48 pruned tree
------------------
age = less30
| student = yes: yes (2.0)
| student = no: no (3.0)
age = 30to40: yes (4.0)
age = more40
| credit_rating = fair: yes (3.0)
| credit_rating = excellent: no (2.0)
Number of Leaves : 5
Size of the tree : 8
Time taken to build model: 0 seconds
=== Evaluation on training set ===
Time taken to test model on training data: 0 seconds
=== Summary ===
Correctly Classified Instances 14 100 %
Incorrectly Classified Instances 0 0 %
Kappa statistic 1
Mean absolute error 0
Root mean squared error 0
Relative absolute error 0 %
Root relative squared error 0 %
Total Number of Instances 14
=== Detailed Accuracy By Class ===
TP Rate FP Rate Precision Recall F-Measure MCC ROC Area PRC Area Class
1.000 0.000 1.000 1.000 1.000 1.000 1.000 1.000 yes
1.000 0.000 1.000 1.000 1.000 1.000 1.000 1.000 no
Weighted Avg. 1.000 0.000 1.000 1.000 1.000 1.000 1.000 1.000
=== Confusion Matrix ===
a b <-- classified as
9 0 | a = yes
0 5 | b = no
其中的树结构:
age = less30 | student = yes: yes (2.0) | student = no: no (3.0) age = 30to40: yes (4.0) age = more40 | credit_rating = fair: yes (3.0) | credit_rating = excellent: no (2.0)
用图画出来是这样:
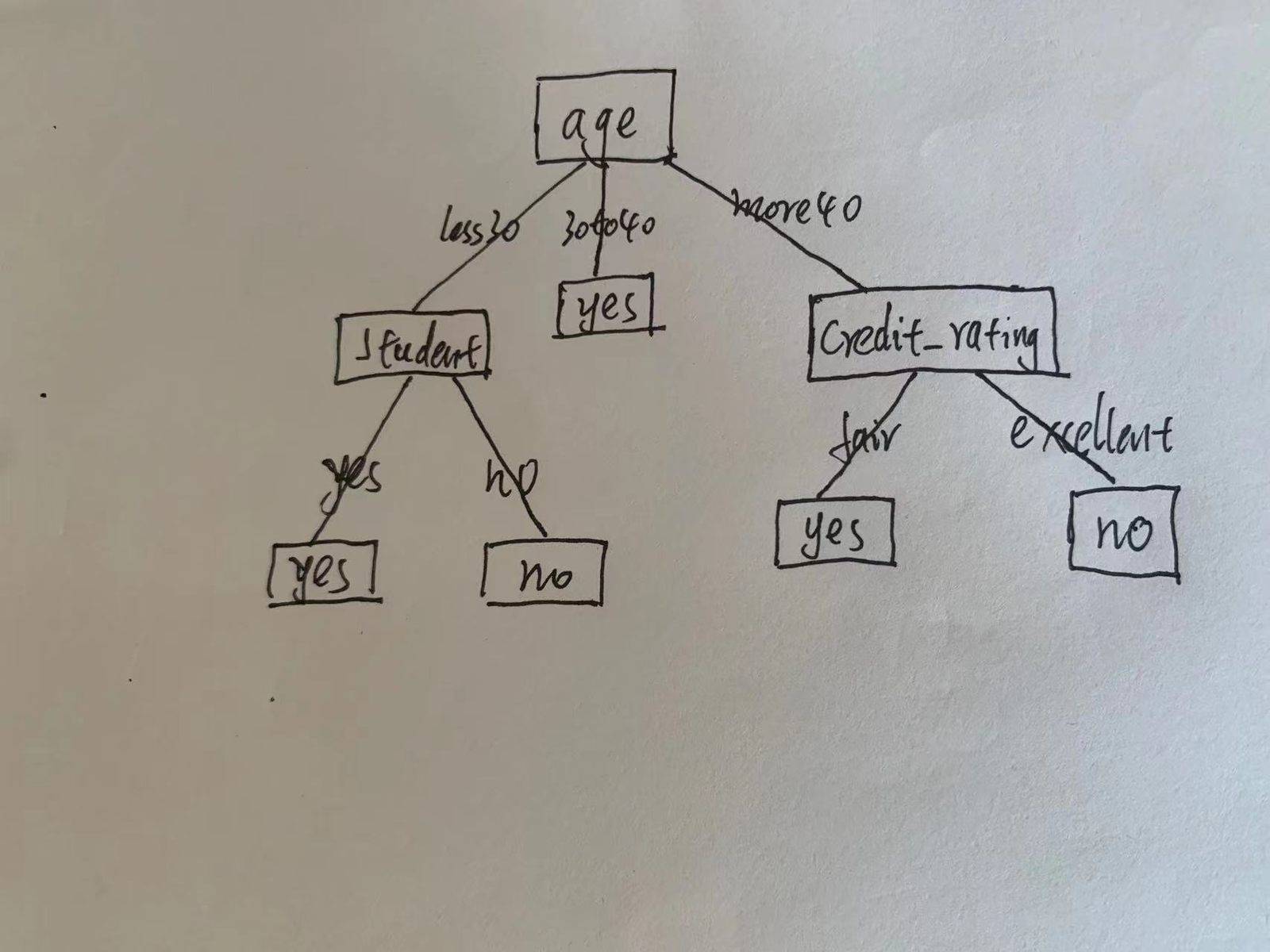
也可看出我们用java生成的决策树(http://www.highersoft.net/html/notice/notice_656.html)是一样的。
这个图有几点得说明一下,为什么节点数少于特征数?
1.并非所有特征都有结点,比如income特征,两分类机率都相等,没区分度,熵比较小,所以没有拿来做分裂函数。
2.每层都拿了所有特征,比较后去掉了较小的熵的特征。
3.父级已经能分类就无需再加子节点了,比如30<age<40的情况。
上面是用weka GUI生成模型,现用代码创建:
package net.highersoft.weka;
import java.io.File;
import weka.classifiers.Classifier;
import weka.core.Instances;
import weka.core.SerializationHelper;
import weka.core.converters.ArffLoader;
public class CreateModel {
public static void main(String args[]) {
try {
// read the training set
Classifier m_classifier = (Classifier) Class.forName("weka.classifiers.trees.J48").getDeclaredConstructor()
.newInstance();// 初始化分类器
File inputFile = new File(
"/Users/chengzhong/code/eclipse-workspace-highersoft/wekamodel/file/buy_compute.arff");// 训练语料文件
ArffLoader atf = new ArffLoader();
atf.setFile(inputFile);
Instances instancesTrain = atf.getDataSet(); // 读入训练文件
atf.setFile(inputFile);
/*
Instances instancesTest = atf.getDataSet(); // 读入测试文件
instancesTest.setClassIndex(0); // 设置分类属性所在行号(第一行为0号),instancesTest.numAttributes()能够取得属性总数
double sum = instancesTest.numInstances(), // 测试语料实例数
right = 0.0f;
*/
instancesTrain.setClassIndex(instancesTrain.numAttributes() - 1);
m_classifier.buildClassifier(instancesTrain); // 训练
System.out.println(m_classifier);
// 保存模型
SerializationHelper.write("/Users/chengzhong/Desktop/weka_buy_compute_J48_java.model", m_classifier);// 参数一为模型保存文件,classifier4为要保存的模型
} catch (Exception e) {
e.printStackTrace();
}
}
}
二、用代码预测
准备arff文件,用训练的arff文件,只体留定义部分(去掉data里的所有数据)准备上面导出的weka_buy_compute_J48.model
代码如下:
package net.highersoft.weka;
import java.io.File;
import java.io.FileInputStream;
import com.google.gson.Gson;
import weka.classifiers.meta.LogitBoost;
import weka.classifiers.trees.J48;
import weka.core.DenseInstance;
import weka.core.Instance;
import weka.core.Instances;
import weka.core.SerializationHelper;
import weka.core.converters.ConverterUtils.DataSource;
public class DecsionTree {
public static void main(String[] args) throws Exception{
File inputFile = new File("/Users/chengzhong/Desktop/weka_buy_compute_J48_java.model");
J48 classifier = (J48) SerializationHelper.read(new FileInputStream(inputFile));
//逻辑回归
//File inputFile = new File("/Users/chengzhong/Desktop/weka_buy_compute_LogitBoost.model");
//LogitBoost classifier = (LogitBoost) SerializationHelper.read(new FileInputStream(inputFile));
Instance instance = new DenseInstance(5);
String file = "/Users/chengzhong/code/eclipse-workspace-highersoft/wekamodel/file/buy_compute_title.arff";
Instances ins = DataSource.read(file);
ins.setClassIndex(4);//设置分类属性所在列号(第一列为0号)
instance.setDataset(ins);
instance.setValue(0, "more40");
instance.setValue(1, "high");
instance.setValue(2,"yes");
instance.setValue(3,"excellent");
instance.setValue(4,"no");
double predicted = classifier.classifyInstance(instance);
System.out.println("predicted:" + predicted);
double[] vals = classifier.distributionForInstance(instance);
System.out.print("instance:\r\n\t" );
for(int i=0;i<instance.numAttributes();i++) {
//instance.attribute(i).indexOfValue(instance.attribute(i).name())
System.out.print(instance.attribute(i).name()+":"+ instance.stringValue(instance.attribute(i)) +"\t");
}
System.out.println();
System.out.println("distribution predicted:" + new Gson().toJson(vals));
System.out.println("real class:" + instance.classValue());
}
}
pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>net.highersoft</groupId>
<artifactId>model</artifactId>
<version>0.0.1-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>nz.ac.waikato.cms.weka</groupId>
<artifactId>weka-stable</artifactId>
<version>3.8.5</version>
</dependency>
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.8.7</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.30</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.30</version>
</dependency>
</dependencies>
</project>输出:
predicted:1.0 instance: age:more40 income:high student:yes credit_rating:excellent buys_computer:no distribution predicted:[0.0,1.0] real class:1.0可以看到预测为1.0(两分类的第2类,也就是no),符合预期。
相关阅读
评论:
↓ 广告开始-头部带绿为生活 ↓
↑ 广告结束-尾部支持多点击 ↑